纺织学报 ›› 2024, Vol. 45 ›› Issue (07): 165-172.doi: 10.13475/j.fzxb.20230704201
陆寅雯1, 侯珏1,2,3, 杨阳1,2, 顾冰菲1, 张宏伟4, 刘正2,3,5( )
)
LU Yinwen1, HOU Jue1,2,3, YANG Yang1,2, GU Bingfei1, ZHANG Hongwei4, LIU Zheng2,3,5()
摘要:
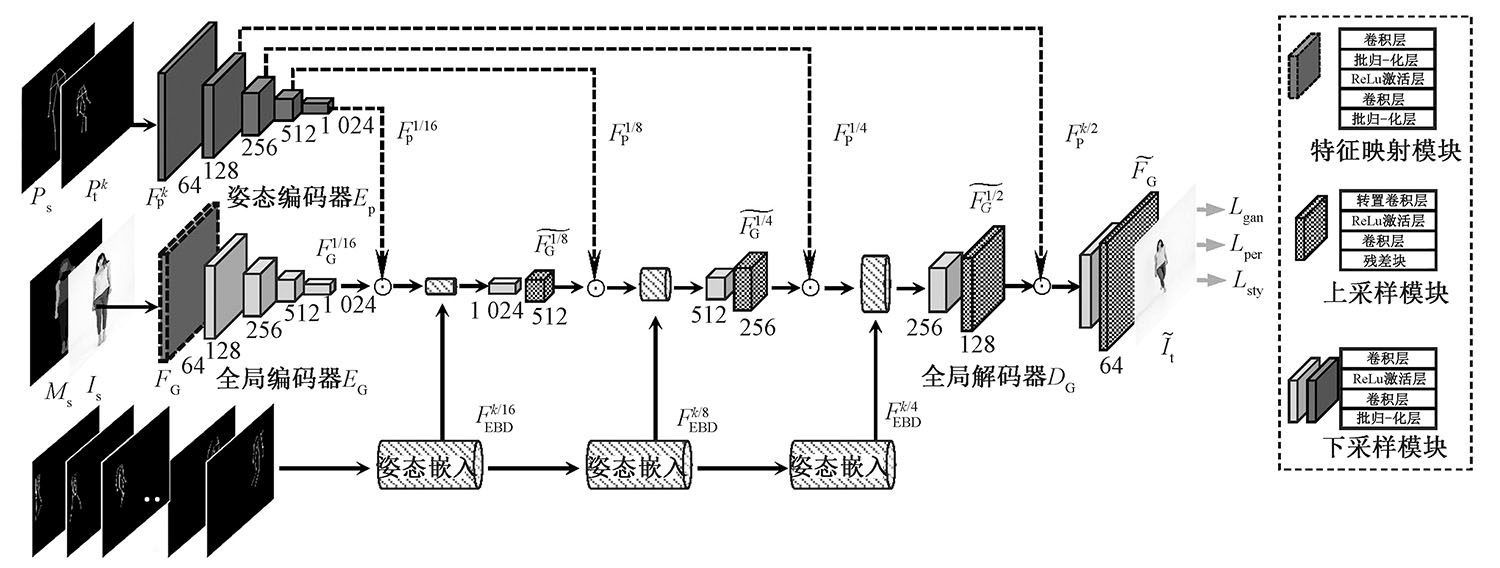
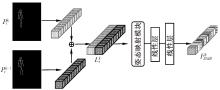
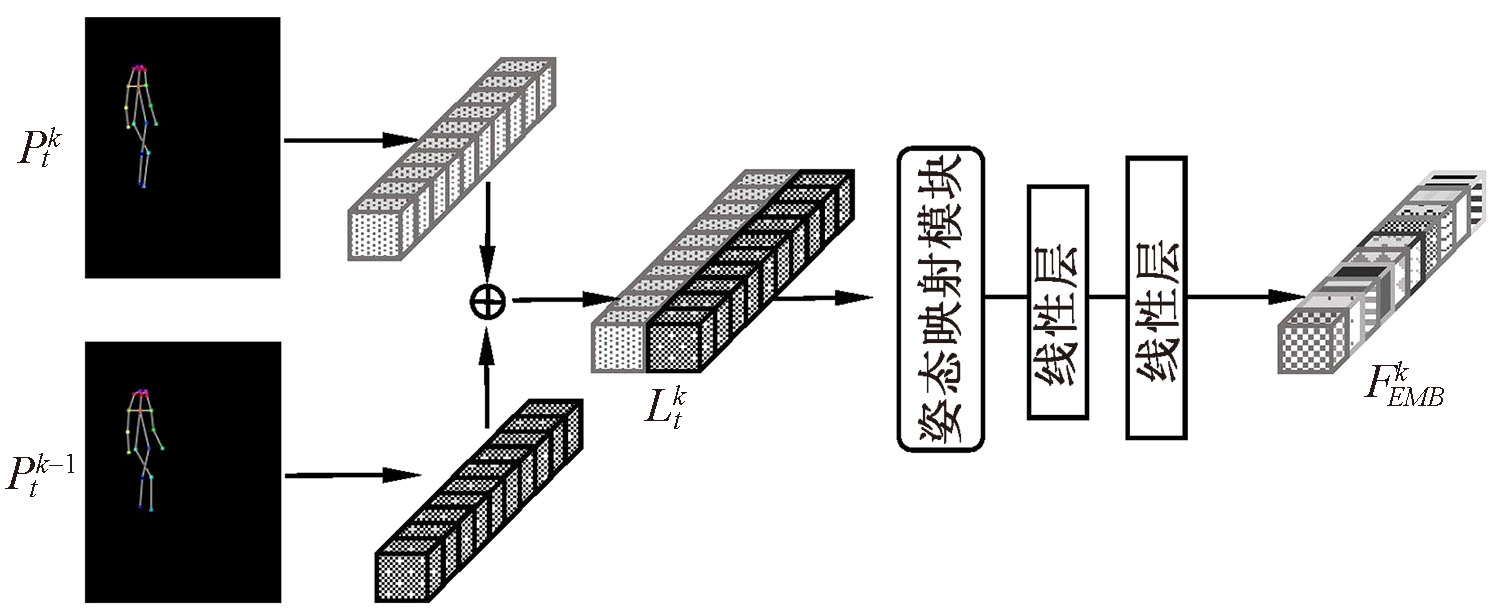
基于单张着装图像生成视频在虚拟试衣和三维重建等领域有重要应用,但现有方法存在生成帧之间动作不连贯、生成视频质量差、人物服装细节缺失等问题,为此提出一种基于姿态嵌入机制以及多尺度注意链接的生成对抗网络模型。首先采用位置嵌入方法,对相邻帧间动作建模,然后针对每个分辨率尺度的特征添加注意力链接,同时在训练过程中输入人物解析图像,最后在服装视频合成数据集的测试集合上进行结果验证。结果表明:本文模型比当前单张着装图像生成视频主流模型在定性结果与定量结果指标上均有所提高,其中峰值信噪比和运动矢量分别为20.89和0.108 4,说明本文模型能够有效提高视频生成的质量与帧间动作的稳定性,为着装人物视频合成提供了新模型。
中图分类号:
| [1] | 张颖, 刘成霞. 生成对抗网络在虚拟试衣中的应用研究进展[J]. 丝绸, 2021, 58(12):63-72. |
| ZHANG Yin, LIU Chengxia. Research progress on the application of generative adversarial network in virtual fitting[J]. Journal of Silk, 2021, 58(12):63-72. | |
| [2] | 王晨麟, 赵正, 张涛, 等. 面向微运动视频的三维重建[J]. 计算机系统应用, 2022, 31(7):298-306. |
| WANG Chenglin, ZHAO Zheng, ZHANG Tao, et al. Iterative reconstruction for micro motion video[J]. Computer System Applications, 2022, 31(7):298-306. | |
| [3] | CAI H, BAI C, TAI Y, et al. Deep video generation, prediction and completion of human action seque-nces[C]// Proceedings of the European conference on computer vision (ECCV). Berlin: Springer-Verlag, 2018: 366-382. |
| [4] | VILLEGAS R, YANG J, HONG S, et al. Decomposing motion and content for natural video sequence predic-tion[C]// 5th International Conference on Learning Representations (ICLR). Addis Ababa: International Conference on Learning Representations, 2017:1-22. |
| [5] | WALKER J, MARINO K, GUPTA A, et al. The pose knows: video forecasting by generating pose futures[C]// Proceedings of the IEEE International Conference On Computer Vision. New York: IEEE Communications Society, 2017: 3332-3341. |
| [6] | MATHIEU M, COUPRIE C, LECUN Y. Deep multi-scale video prediction beyond mean square error[C]// 4th International Conference on Learning Representations (ICLR). Addis Ababa: International Conference on Learning Representations, 2016:1-14. |
| [7] | HU Q, WALCHLI A, PORTENIER T, et al. Learning to take directions one step at a time[C]// 2020 25th International Conference on Pattern Recognition (ICPR). Montreal: IEEE Communications Society, 2020:1-8. |
| [8] | DONG H, LIANG X, SHEN X, et al. Fw-gan: flow-navigated warping gan for video virtual try-on[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. New York: IEEE Communications Society, 2019: 1161-1170. |
| [9] | ZHU Z, HUANG T, SHI B, et al. Progressive pose attention transfer for person image generation[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Communications Society, 2019: 2347-2356. |
| [10] | ZHAO Q, ZHENG C, LIU M, et al. PoseFormerV2: exploring frequency domain for efficient and robust 3D human pose estimation[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Communications Society, 2023: 8877-8886. |
| [11] | ISOLA P, ZHU J Y, ZHOU T, et al. Image-to-image translation with conditional adversarial networks[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Communications Society, 2017: 1125-1134. |
| [12] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recog-nition[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Communications Society, 2016: 770-778. |
| [13] | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recog-nition[C]// 3rd International Conference on Learning Representations (ICLR). Addis Ababa: International Conference on Learning Representations, 2015:1-14. |
| [14] | LI P, XU Y, WEI Y, et al. Self-correction for human parsing[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 44(6): 3260-3271. |
| [15] | LOSHCHILOV I, HUTTER F. Decoupled weight decay regularization[C]// International Conference on Learning Representations. Addis Ababa: International Conference on Learning Representations, 2018:23-44. |
| [16] |
WANG Z, BOVIK A C, SHEIKH H R, et al. Image quality assessment: from error visibility to structural similarity[J]. IEEE transactions on image processing, 2004, 13(4): 600-612.
doi: 10.1109/tip.2003.819861 pmid: 15376593 |
| [17] | ZHANG R, ISOLA P, EFROS A A, et al. The unreasonable effectiveness of deep features as a perceptual metric[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Communications Society, 2018: 586-595. |
| [18] | HUYNH Q, GHANBARI M. Scope of validity of PSNR in image/video quality assessment[J]. Electronics letters, 2008, 44(13): 800-801. |
| [19] | ZHANG J, LI K, LAI Y K, et al. Pise: Person image synthesis and editing with decoupled GAN[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Communications Society, 2021: 7982-7990. |
| [20] | ZHOU X, YIN M, CHEN X, et al. Cross attention based style distribution for controllable person image synthesis[C]// Computer Vision-ECCV 2022: 17th European Conference. Berlin: Springer-Verlag, 2022: 161-178. |
| [1] | 文嘉琪, 李新荣, 冯文倩, 李瀚森. 印花面料的边缘轮廓快速提取方法[J]. 纺织学报, 2024, 45(05): 165-173. |
| [2] | 顾梅花, 花玮, 董晓晓, 张晓丹. 基于上下文提取与注意力融合的遮挡服装图像分割[J]. 纺织学报, 2024, 45(05): 155-164. |
| [3] | 胡旭东, 汤炜, 曾志发, 汝欣, 彭来湖, 李建强, 王博平. 基于轻量化卷积神经网络的纬编针织物组织结构分类[J]. 纺织学报, 2024, 45(05): 60-69. |
| [4] | 陆伟健, 屠佳佳, 王俊茹, 韩思捷, 史伟民. 基于改进残差网络的空纱筒识别模型[J]. 纺织学报, 2024, 45(01): 194-202. |
| [5] | 池盼盼, 梅琛楠, 王焰, 肖红, 钟跃崎. 基于边缘填充的单兵迷彩伪装小目标检测[J]. 纺织学报, 2024, 45(01): 112-119. |
| [6] | 师红宇, 位营杰, 管声启, 李怡. 基于残差结构的棉花异性纤维检测算法[J]. 纺织学报, 2023, 44(12): 35-42. |
| [7] | 马创佳, 齐立哲, 高晓飞, 王子恒, 孙云权. 基于改进YOLOv4-Tiny的缝纫线迹质量检测方法[J]. 纺织学报, 2023, 44(08): 181-188. |
| [8] | 袁甜甜, 王鑫, 罗炜豪, 梅琛楠, 韦京艳, 钟跃崎. 基于注意力机制和视觉转换器的三维虚拟试衣网络[J]. 纺织学报, 2023, 44(07): 192-198. |
| [9] | 付晗, 胡峰, 龚杰, 余联庆. 面向织物疵点检测的缺陷重构方法[J]. 纺织学报, 2023, 44(07): 103-109. |
| [10] | 叶勤文, 王朝晖, 黄荣, 刘欢欢, 万思邦. 虚拟服装迁移在个性化服装定制中的应用[J]. 纺织学报, 2023, 44(06): 183-190. |
| [11] | 刘玉叶, 王萍. 基于纹理特征学习的高精度虚拟试穿智能算法[J]. 纺织学报, 2023, 44(05): 177-183. |
| [12] | 杨宏脉, 张效栋, 闫宁, 朱琳琳, 李娜娜. 一种高鲁棒性经编机上断纱在线检测算法[J]. 纺织学报, 2023, 44(05): 139-146. |
| [13] | 顾冰菲, 张健, 徐凯忆, 赵崧灵, 叶凡, 侯珏. 复杂背景下人体轮廓及其参数提取[J]. 纺织学报, 2023, 44(03): 168-175. |
| [14] | 李杨, 彭来湖, 李建强, 刘建廷, 郑秋扬, 胡旭东. 基于深度信念网络的织物疵点检测[J]. 纺织学报, 2023, 44(02): 143-150. |
| [15] | 王斌, 李敏, 雷承霖, 何儒汉. 基于深度学习的织物疵点检测研究进展[J]. 纺织学报, 2023, 44(01): 219-227. |
|
||
 京公网安备11010502044800号
京公网安备11010502044800号