纺织学报 ›› 2024, Vol. 45 ›› Issue (09): 164-174.doi: 10.13475/j.fzxb.20230904501
侯珏1,2, 丁焕1, 杨阳1,2, 陆寅雯1, 余灵婕3, 刘正2,4( )
)
HOU Jue1,2, DING Huan1, YANG Yang1,2, LU Yinwen1, YU Lingjie3, LIU Zheng2,4()
摘要:
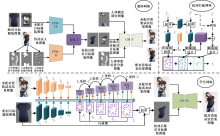
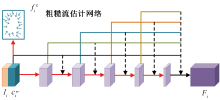
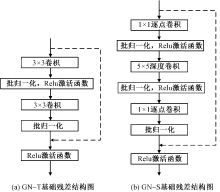
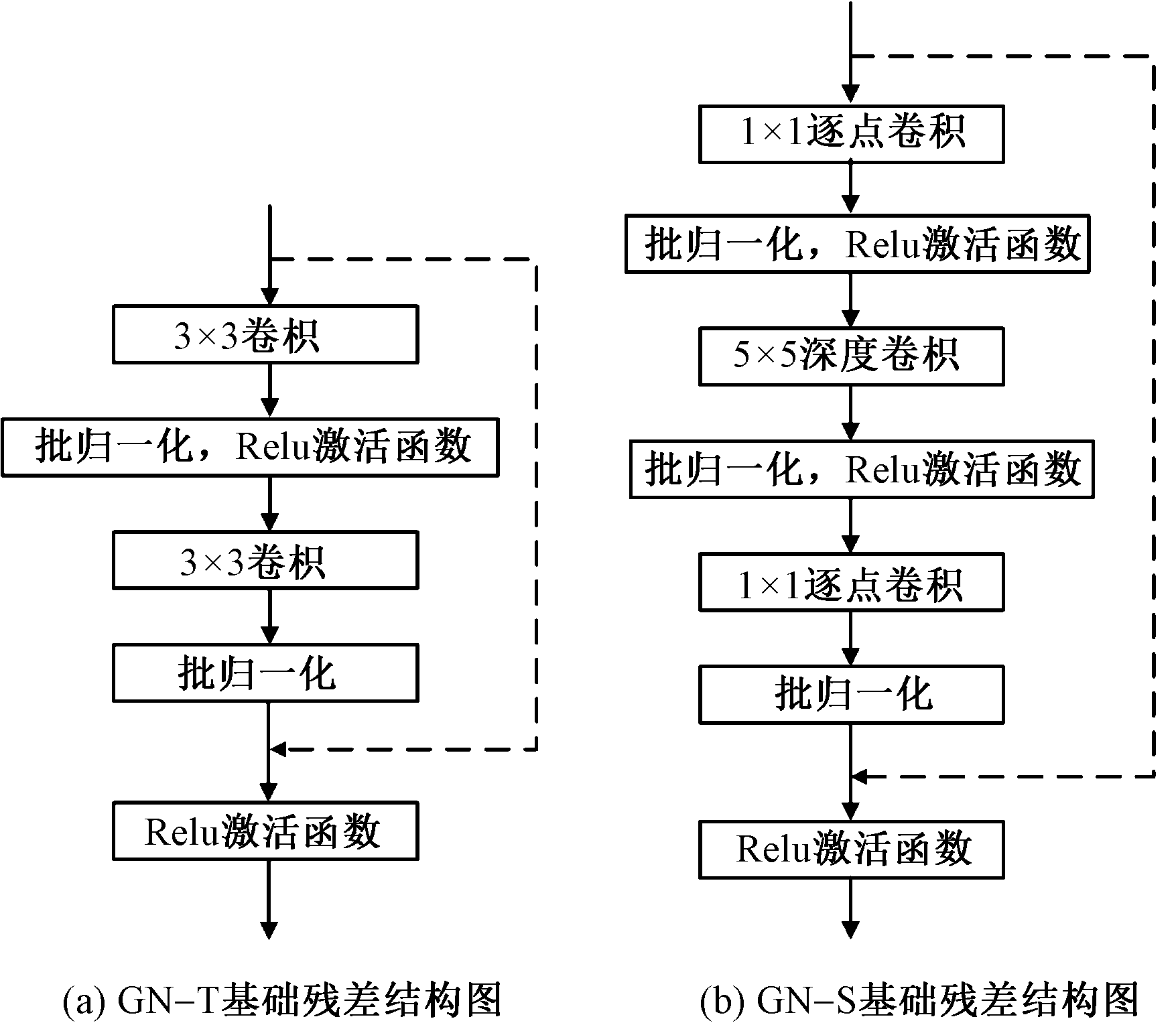
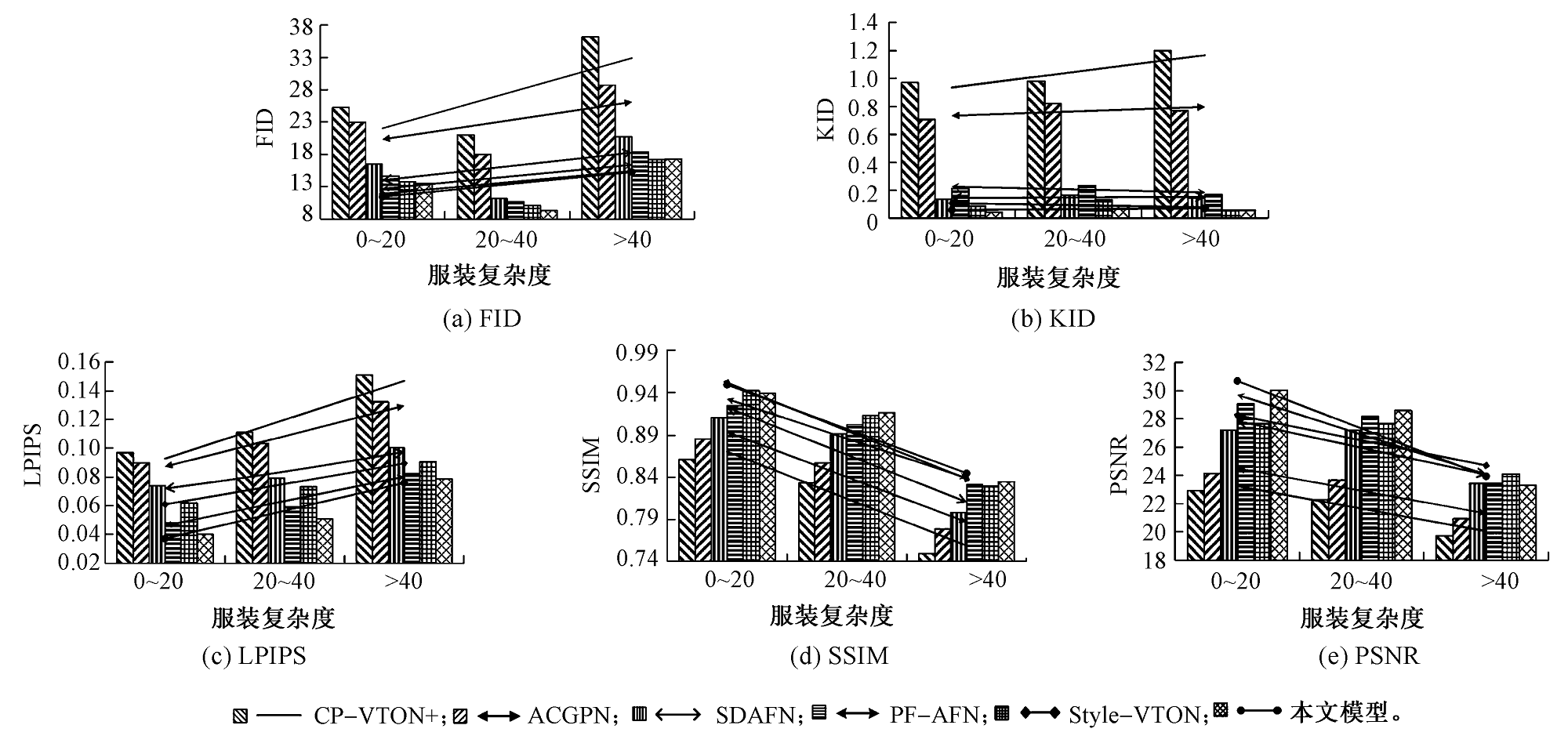
基于外观流的二维虚拟试衣技术存在着服装扭曲准确率低、纹理失真以及模型计算成本高等问题,提出了一种基于混合知识蒸馏和特征增强的轻量级无解析式虚拟试衣模型。首先,通过全局特征的融合与不同尺度下流场运算结果的校准,提出了改进后的外观流估计方法,提高外观流的估计精度;其次,采用知识蒸馏的方法对图像分割结果与虚拟试衣流程进行解耦,构建了基于深度可分离卷积的轻量级试衣网络;最后,提出了基于像素平均梯度的服装复杂度GTC指标量化分析服装的纹理复杂程度,以此为基础将VITON数据集划分为简易纹理集、较复杂纹理集和复杂纹理集。结果表明:提出的模型在图像质量评价指标(弗雷歇距离、感知图像块相似度、峰值信噪比、内核初始距离)上的分值较目前性能最优的模型均有所提升,能够有效提高服装扭曲准确度与试穿结果图像的质量,缓解服装纹理畸变与失真的问题,同时还拥有更小的模型尺寸和更快的运行推理速度。
中图分类号:
| [1] | BHATNAGAR B L, TIWARI G, THEOBALT C, et al. Multi-garment net: learning to dress 3D people from images[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul, Korea: IEEE, 2019: 5420-5430. |
| [2] | MIR A, ALLDIECK T, PONS-MOLL G. Learning to transfer texture from clothing images to 3D humans[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, WA, USA: IEEE, 2020: 7023-7034. |
| [3] | ZHAO F, XIE Z, KAMPFFMEYER M, et al. M3D-VTON: a monocular-to-3D virtual try-on network[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal, Canada: IEEE, 2021: 13239-13249. |
| [4] | DUCHON J. Splines minimizing rotation-invariant semi-norms in sobolev spaces[C]// Proceedings of the Constructive Theory of Functions of Several Variables. Berlin:Springer, 1977: 85-100. |
| [5] | GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[J]. Advances in Neural Information Processing Systems, 2014, 27(4): 2670-2680. |
| [6] | HAN X, WU Z, WU Z, et al. Viton: an image-based virtual try-on network[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 7543-7552. |
| [7] | GONG K, LIANG X, ZHANG D, et al. Look into person: self-supervised structure-sensitive learning and a new benchmark for human parsing[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017: 932-940. |
| [8] | CAO Z, SIMON T, WEI S-E, et al. Realtime multi-person 2D pose estimation using part affinity fields[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017: 7291-7299. |
| [9] | HAN X, HU X, HUANG W, et al. Clothflow: a flow-based model for clothed person generation[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul, Korea: IEEE, 2019: 10471-10480. |
| [10] | CHOPRA A, JAIN R, HEMANI M, et al. Zflow: gated appearance flow-based virtual try-on with 3D priors[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal, QC, Canada: IEEE, 2021: 5433-5442. |
| [11] | LEE S, GU G, PARK S, et al. High-resolution virtual try-on with misalignment and occlusion-handled conditions[C]// Proceedings of the European Conference on Computer Vision. Tel-Aviv, Israel: Springer, 2022: 204-219. |
| [12] | XIE Z, HUANG Z, DONG X, et al. GP-VTON: Towards general purpose virtual try-on via collaborative local-flow global-parsing learning[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver, BC, Canada: IEEE, 2023: 23550-23559. |
| [13] | BAI S, ZHOU H, LI Z, et al. Single stage virtual try-on via deformable attention flows[C]// Proceedings of the European Conference on Computer Vision. Tel-Aviv, Israel: Springer, 2022: 409-425. |
| [14] | GE Y, SONG Y, ZHANG R, et al. Parser-free virtual try-on via distilling appearance flows[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, TN, USA: IEEE, 2021: 8485-8493. |
| [15] | HE S, SONG Y Z, XIANG T. Style-based global appearance flow for virtual try-on[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, LA, USA: IEEE, 2022: 3470-3479. |
| [16] | KARRAS T, LAINE S, AILA T. A style-based generator architecture for generative adversarial networks[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, CA, USA: IEEE, 2019: 4401-4410. |
| [17] | GÜLER R A, NEVEROVA N, KOKKINOS I. Densepose: ense human pose estimation in the wild[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 7297-7306. |
| [18] | LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017: 2117-2125. |
| [19] | RONNEBERGER O, FISCHER P, BROX T. U-net: Convolutional networks for biomedical image segmentation[C]// Proceedings of the Medical Image Computing and Computer-Assisted Intervention:MICCAI 2015. Munich, Germany: Springer, 2015: 234-241. |
| [20] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016: 770-778. |
| [21] | CHOLLET F. Xception: deep learning with depthwise separable convolutions[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017: 1251-1258. |
| [22] | SANDLER M, HOWARD A, ZHU M, et al. Mobilenetv2: inverted residuals and linear bottle-necks[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 4510-4520. |
| [23] | JOHNSON J, ALAHI A, FEI-FEI L. Perceptual losses for real-time style transfer and super-resolution[C]// Proceedings of the Computer Vision:ECCV 2016. Amsterdam, The Netherlands: Springer, 2016: 694-711. |
| [24] | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recogni-tion[J]. Computer Science, 2014. DOI: 10.48550/arXiv.1409.1556. |
| [25] | SUN D, ROTH S, BLACK M J. A quantitative analysis of current practices in optical flow estimation and the principles behind them[J]. International Journal of Computer Vision, 2014(106): 115-137. |
| [26] | HEUSEL M, RAMSAUER H, UNTERTHINER T, et al. Gans trained by a two time-scale update rule converge to a local nash equilibrium[J]. Advances in Neural Information Processing Systems, 2017(30): 6626-6637. |
| [27] |
WANG Z, BOVIK A C, SHEIKH H R, et al. Image quality assessment: from error visibility to structural similarity[J]. IEEE Transactions on Image Processing, 2004, 13(4): 600-612.
doi: 10.1109/tip.2003.819861 pmid: 15376593 |
| [28] | ZHANG R, ISOLA P, EFROS A A, et al. The unreasonable effectiveness of deep features as a perceptual metric[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 586-595. |
| [29] | SUTHERLAND J D, ARBEL M, GRETTON A. Demystifying mmd gans[C]// International Conference on Learning Representations. Vancouver, Canada: ICLR, 2018: 1-36. |
| [30] | HORE A, ZIOU D. Image quality metrics: PSNR vs. SSIM[C]// Proceedings of the 2010 20th International Conference on Pattern Recognition. Istanbul, Turkey: IEEE, 2010: 2366-2369. |
| [31] | MINAR M R. TUAN T T, AHN H, et al. Cp-vton+: clothing shape and texture preserving image-based virtual try-on[C]// Proceedings of the CVPR Workshops. Seattle, WA, USA: IEEE, 2020: 10-14. |
| [32] | YANG H, ZHANG R, GUO X, et al. Towards photo-realistic virtual try-on by adaptively generating-preserving image content[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, WA, USA: IEEE, 2020: 7850-7859. |
| [33] | YANG H, YU X, LIU Z. Full-range virtual try-on with recurrent tri-level transform[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, LA, USA: IEEE, 2022: 3460-3469. |
| [1] | 陆寅雯, 侯珏, 杨阳, 顾冰菲, 张宏伟, 刘正. 基于姿态嵌入机制和多尺度注意力的单张着装图像视频合成[J]. 纺织学报, 2024, 45(07): 165-172. |
| [2] | 任国栋, 屠佳佳, 李杨, 邱子安, 史伟民. 基于轻量化网络和知识蒸馏的纱线状态检测[J]. 纺织学报, 2023, 44(09): 205-212. |
| [3] | 袁甜甜, 王鑫, 罗炜豪, 梅琛楠, 韦京艳, 钟跃崎. 基于注意力机制和视觉转换器的三维虚拟试衣网络[J]. 纺织学报, 2023, 44(07): 192-198. |
| [4] | 叶勤文, 王朝晖, 黄荣, 刘欢欢, 万思邦. 虚拟服装迁移在个性化服装定制中的应用[J]. 纺织学报, 2023, 44(06): 183-190. |
| [5] | 鲁虹, 宋佳怡, 李圆圆, 滕峻峰. 基于合体两片袖的内旋造型结构设计[J]. 纺织学报, 2022, 43(08): 140-146. |
| [6] | 王春茹, 袁月, 曹晓梦, 范依琳, 钟安华. 立领结构参数对服装造型的影响[J]. 纺织学报, 2022, 43(03): 153-159. |
| [7] | 张益洁, 李涛, 吕叶馨, 杜磊, 邹奉元. 服装松量设计及表征模型构建研究进展[J]. 纺织学报, 2021, 42(04): 184-190. |
| [8] | 陈咪, 叶勤文, 张皋鹏. 斜裁裙参数化结构模型的构建[J]. 纺织学报, 2020, 41(07): 135-140. |
| [9] | 夏海浜, 黄鸿云, 丁佐华. 基于迁移学习与支持向量机的服装舒适度评估[J]. 纺织学报, 2020, 41(06): 125-131. |
| [10] | 许倩, 陈敏之. 基于深度学习的服装丝缕平衡性评价系统[J]. 纺织学报, 2019, 40(10): 191-195. |
|
||
 京公网安备11010502044800号
京公网安备11010502044800号