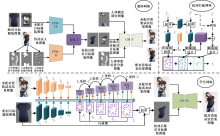
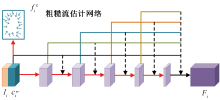
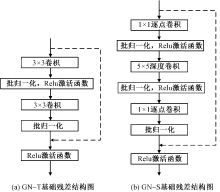
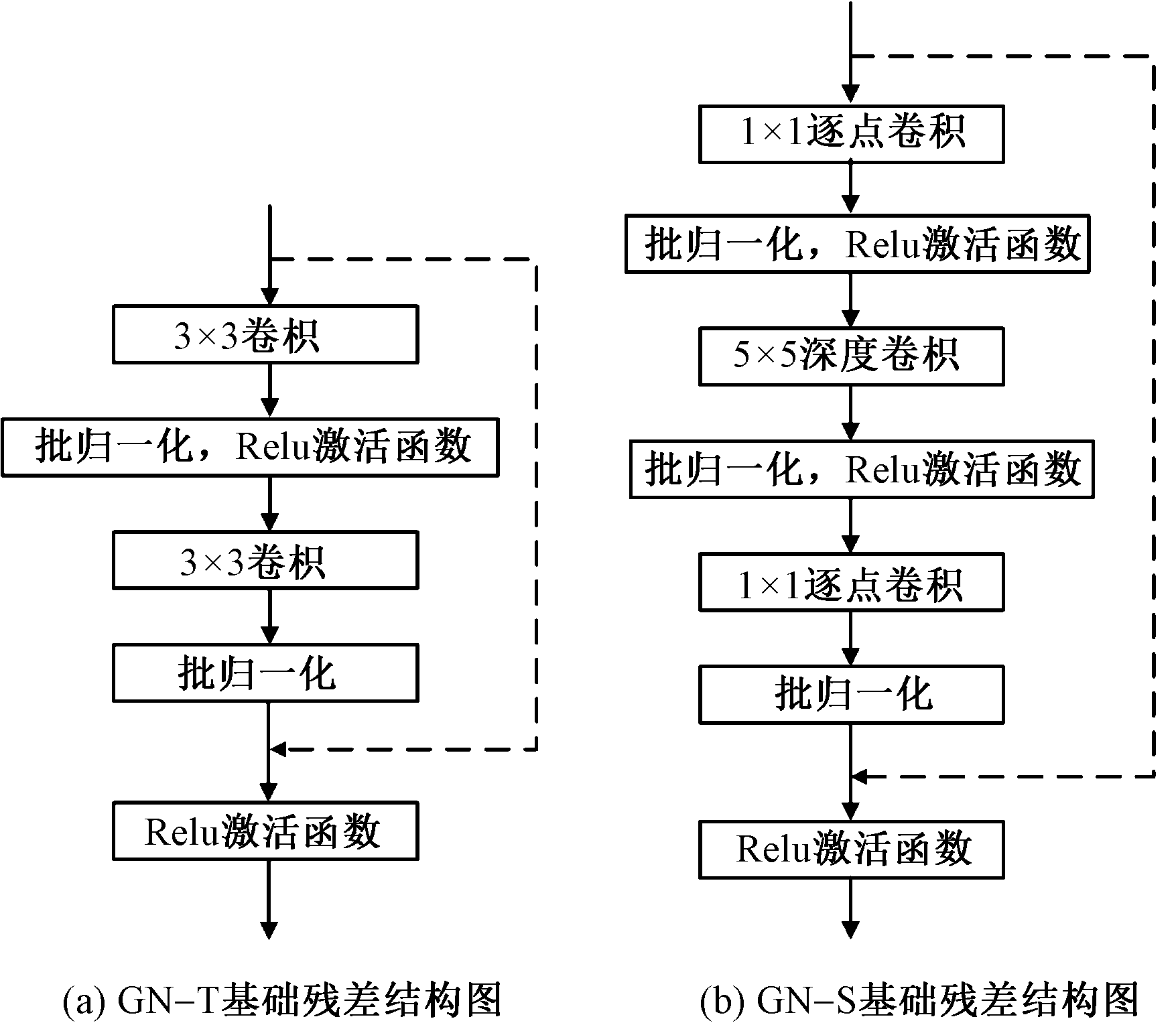
Journal of Textile Research ›› 2024, Vol. 45 ›› Issue (09): 164-174.doi: 10.13475/j.fzxb.20230904501
• Apparel Engineering • Previous Articles Next Articles
HOU Jue1,2, DING Huan1, YANG Yang1,2, LU Yinwen1, YU Lingjie3, LIU Zheng2,4( )
)
CLC Number:
| [1] | BHATNAGAR B L, TIWARI G, THEOBALT C, et al. Multi-garment net: learning to dress 3D people from images[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul, Korea: IEEE, 2019: 5420-5430. |
| [2] | MIR A, ALLDIECK T, PONS-MOLL G. Learning to transfer texture from clothing images to 3D humans[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, WA, USA: IEEE, 2020: 7023-7034. |
| [3] | ZHAO F, XIE Z, KAMPFFMEYER M, et al. M3D-VTON: a monocular-to-3D virtual try-on network[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal, Canada: IEEE, 2021: 13239-13249. |
| [4] | DUCHON J. Splines minimizing rotation-invariant semi-norms in sobolev spaces[C]// Proceedings of the Constructive Theory of Functions of Several Variables. Berlin:Springer, 1977: 85-100. |
| [5] | GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[J]. Advances in Neural Information Processing Systems, 2014, 27(4): 2670-2680. |
| [6] | HAN X, WU Z, WU Z, et al. Viton: an image-based virtual try-on network[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 7543-7552. |
| [7] | GONG K, LIANG X, ZHANG D, et al. Look into person: self-supervised structure-sensitive learning and a new benchmark for human parsing[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017: 932-940. |
| [8] | CAO Z, SIMON T, WEI S-E, et al. Realtime multi-person 2D pose estimation using part affinity fields[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017: 7291-7299. |
| [9] | HAN X, HU X, HUANG W, et al. Clothflow: a flow-based model for clothed person generation[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul, Korea: IEEE, 2019: 10471-10480. |
| [10] | CHOPRA A, JAIN R, HEMANI M, et al. Zflow: gated appearance flow-based virtual try-on with 3D priors[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal, QC, Canada: IEEE, 2021: 5433-5442. |
| [11] | LEE S, GU G, PARK S, et al. High-resolution virtual try-on with misalignment and occlusion-handled conditions[C]// Proceedings of the European Conference on Computer Vision. Tel-Aviv, Israel: Springer, 2022: 204-219. |
| [12] | XIE Z, HUANG Z, DONG X, et al. GP-VTON: Towards general purpose virtual try-on via collaborative local-flow global-parsing learning[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver, BC, Canada: IEEE, 2023: 23550-23559. |
| [13] | BAI S, ZHOU H, LI Z, et al. Single stage virtual try-on via deformable attention flows[C]// Proceedings of the European Conference on Computer Vision. Tel-Aviv, Israel: Springer, 2022: 409-425. |
| [14] | GE Y, SONG Y, ZHANG R, et al. Parser-free virtual try-on via distilling appearance flows[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, TN, USA: IEEE, 2021: 8485-8493. |
| [15] | HE S, SONG Y Z, XIANG T. Style-based global appearance flow for virtual try-on[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, LA, USA: IEEE, 2022: 3470-3479. |
| [16] | KARRAS T, LAINE S, AILA T. A style-based generator architecture for generative adversarial networks[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, CA, USA: IEEE, 2019: 4401-4410. |
| [17] | GÜLER R A, NEVEROVA N, KOKKINOS I. Densepose: ense human pose estimation in the wild[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 7297-7306. |
| [18] | LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017: 2117-2125. |
| [19] | RONNEBERGER O, FISCHER P, BROX T. U-net: Convolutional networks for biomedical image segmentation[C]// Proceedings of the Medical Image Computing and Computer-Assisted Intervention:MICCAI 2015. Munich, Germany: Springer, 2015: 234-241. |
| [20] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016: 770-778. |
| [21] | CHOLLET F. Xception: deep learning with depthwise separable convolutions[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017: 1251-1258. |
| [22] | SANDLER M, HOWARD A, ZHU M, et al. Mobilenetv2: inverted residuals and linear bottle-necks[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 4510-4520. |
| [23] | JOHNSON J, ALAHI A, FEI-FEI L. Perceptual losses for real-time style transfer and super-resolution[C]// Proceedings of the Computer Vision:ECCV 2016. Amsterdam, The Netherlands: Springer, 2016: 694-711. |
| [24] | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recogni-tion[J]. Computer Science, 2014. DOI: 10.48550/arXiv.1409.1556. |
| [25] | SUN D, ROTH S, BLACK M J. A quantitative analysis of current practices in optical flow estimation and the principles behind them[J]. International Journal of Computer Vision, 2014(106): 115-137. |
| [26] | HEUSEL M, RAMSAUER H, UNTERTHINER T, et al. Gans trained by a two time-scale update rule converge to a local nash equilibrium[J]. Advances in Neural Information Processing Systems, 2017(30): 6626-6637. |
| [27] |
WANG Z, BOVIK A C, SHEIKH H R, et al. Image quality assessment: from error visibility to structural similarity[J]. IEEE Transactions on Image Processing, 2004, 13(4): 600-612.
doi: 10.1109/tip.2003.819861 pmid: 15376593 |
| [28] | ZHANG R, ISOLA P, EFROS A A, et al. The unreasonable effectiveness of deep features as a perceptual metric[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 586-595. |
| [29] | SUTHERLAND J D, ARBEL M, GRETTON A. Demystifying mmd gans[C]// International Conference on Learning Representations. Vancouver, Canada: ICLR, 2018: 1-36. |
| [30] | HORE A, ZIOU D. Image quality metrics: PSNR vs. SSIM[C]// Proceedings of the 2010 20th International Conference on Pattern Recognition. Istanbul, Turkey: IEEE, 2010: 2366-2369. |
| [31] | MINAR M R. TUAN T T, AHN H, et al. Cp-vton+: clothing shape and texture preserving image-based virtual try-on[C]// Proceedings of the CVPR Workshops. Seattle, WA, USA: IEEE, 2020: 10-14. |
| [32] | YANG H, ZHANG R, GUO X, et al. Towards photo-realistic virtual try-on by adaptively generating-preserving image content[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, WA, USA: IEEE, 2020: 7850-7859. |
| [33] | YANG H, YU X, LIU Z. Full-range virtual try-on with recurrent tri-level transform[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, LA, USA: IEEE, 2022: 3460-3469. |
|
||